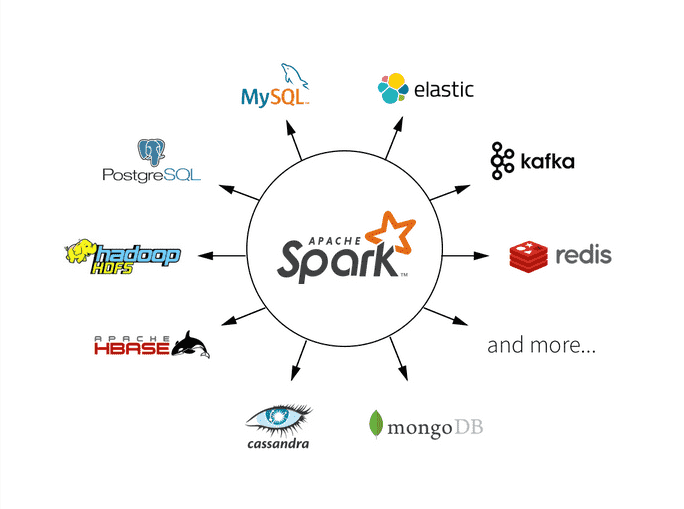
अपाचे स्पार्क म्हणजे काय?
Apache Spark ही एक मुक्त-स्रोत, वितरित प्रक्रिया प्रणाली आहे जी मोठ्या डेटा वर्कलोडसाठी वापरली जाते. हे इन-मेमरी कॅशिंग, आणि कोणत्याही आकाराच्या डेटाच्या विरूद्ध जलद विश्लेषणात्मक क्वेरीसाठी ऑप्टिमाइझ केलेल्या क्वेरी अंमलबजावणीचा वापर करते. हे Java, Scala, Python आणि R मध्ये डेव्हलपमेंट API प्रदान करते आणि एकाधिक वर्कलोड्समध्ये कोडच्या पुनर्वापराला समर्थन देते—बॅच प्रोसेसिंग, इंटरएक्टिव्ह क्वेरी, रिअल-टाइम अॅनालिटिक्स, मशीन लर्निंग आणि आलेख प्रक्रिया. तुम्हाला ते FINRA, Yelp, Zillow, DataXu, Urban Institute आणि CrowdStrike सह कोणत्याही उद्योगातील संस्थांद्वारे वापरलेले आढळेल. Apache Spark सर्वात लोकप्रिय बिग डेटा वितरित प्रोसेसिंग फ्रेमवर्क बनले आहे.अपाचे स्पार्कचा इतिहास काय आहे?
Apache Spark ची सुरुवात 2009 मध्ये UC Berkley's AMPLab येथे एक संशोधन प्रकल्प म्हणून झाली, ज्यामध्ये विद्यार्थी, संशोधक आणि प्राध्यापकांचा समावेश असलेला सहयोग, डेटा-केंद्रित ऍप्लिकेशन डोमेनवर केंद्रित आहे. Hadoop MapReduce ची स्केलेबिलिटी आणि दोष सहिष्णुता राखून, मशीन लर्निंग सारख्या जलद पुनरावृत्ती प्रक्रियेसाठी ऑप्टिमाइझ केलेले, आणि परस्परसंवादी डेटा विश्लेषणासाठी ऑप्टिमाइझ केलेले नवीन फ्रेमवर्क तयार करणे हे स्पार्कचे ध्येय होते. “स्पार्क: क्लस्टर कॉम्प्युटिंग विथ वर्किंग सेट्स” नावाचा पहिला पेपर जून 2010 मध्ये प्रकाशित झाला होता आणि स्पार्कला बीएसडी परवान्याअंतर्गत ओपन सोर्स करण्यात आले होते. जून, 2013 मध्ये, स्पार्कने Apache Software Foundation (ASF) मध्ये उष्मायन स्थितीत प्रवेश केला आणि फेब्रुवारी, 2014 मध्ये अपाचे टॉप-लेव्हल प्रोजेक्ट म्हणून स्थापना केली. स्पार्क स्वतंत्रपणे, Apache Mesos वर किंवा बहुतेक वेळा Apache Hadoop वर चालू शकते.आज, स्पार्क हा हडूप इकोसिस्टममधील सर्वात सक्रिय प्रकल्पांपैकी एक बनला आहे, अनेक संस्थांनी मोठ्या डेटावर प्रक्रिया करण्यासाठी हडूपच्या बरोबरीने स्पार्कचा अवलंब केला आहे. 2017 मध्ये, स्पार्कचे 365,000 मीटअप सदस्य होते, जे दोन वर्षांत 5 पट वाढ दर्शवते. 2009 पासून 200 हून अधिक संस्थांकडून 1,000 हून अधिक विकासकांचे योगदान मिळाले आहे.
अपाचे स्पार्क कसे कार्य करते?
Hadoop MapReduce हे समांतर, वितरित अल्गोरिदमसह मोठ्या डेटा सेटवर प्रक्रिया करण्यासाठी प्रोग्रामिंग मॉडेल आहे. विकासक मोठ्या प्रमाणात समांतर ऑपरेटर लिहू शकतात, कामाचे वितरण आणि दोष सहिष्णुतेबद्दल काळजी न करता. तथापि, MapReduce समोर एक आव्हान आहे ती नोकरी चालवण्यासाठी लागणारी अनुक्रमिक बहु-चरण प्रक्रिया. प्रत्येक चरणासह, MapReduce क्लस्टरमधील डेटा वाचतो, ऑपरेशन्स करतो आणि HDFS वर परिणाम लिहितो. कारण प्रत्येक पायरीसाठी डिस्क वाचणे आणि लिहिणे आवश्यक आहे, डिस्क I/O च्या लेटन्सीमुळे MapReduce जॉब्स धीमे आहेत.मेमरीमध्ये प्रक्रिया करून, जॉबमधील चरणांची संख्या कमी करून आणि एकाधिक समांतर ऑपरेशन्समध्ये डेटाचा पुनर्वापर करून, MapReduce वरील मर्यादा दूर करण्यासाठी स्पार्क तयार करण्यात आला. स्पार्क सह, फक्त एक-चरण आवश्यक आहे जेथे डेटा मेमरीमध्ये वाचला जातो, ऑपरेशन्स केले जातात आणि परिणाम परत लिहिले जातात-परिणामी खूप जलद अंमलबजावणी होते. त्याच डेटासेटवरील फंक्शनला वारंवार कॉल करणार्या मशीन लर्निंग अल्गोरिदमचा वेग वाढवण्यासाठी स्पार्क इन-मेमरी कॅशे वापरून डेटाचा पुनर्वापर देखील करते. डेटाचा पुनर्वापर हा डेटाफ्रेम्सच्या निर्मितीद्वारे पूर्ण केला जातो, रिझिलिएंट डिस्ट्रिब्युटेड डेटासेट (RDD) वर एक अॅब्स्ट्रॅक्शन, जो मेमरीमध्ये कॅश केलेल्या वस्तूंचा संग्रह आहे आणि एकाधिक स्पार्क ऑपरेशन्समध्ये पुन्हा वापरला जातो. हे नाटकीयरित्या MapReduce पेक्षा स्पार्क बनवण्याच्या विलंबता कमी करते, विशेषत: मशीन लर्निंग आणि परस्पर विश्लेषण करताना.
अपाचे स्पार्क वि. अपाचे हडूप
Spark आणि Hadoop MapReduce च्या डिझाईनमधील फरकांव्यतिरिक्त, अनेक संस्थांना हे मोठे डेटा फ्रेमवर्क पूरक असल्याचे आढळले आहे, त्यांचा एकत्रित वापर करून व्यापक व्यावसायिक आव्हान सोडवले आहे.हडूप हे एक ओपन सोर्स फ्रेमवर्क आहे ज्यामध्ये स्टोरेज म्हणून हडूप डिस्ट्रिब्युटेड फाइल सिस्टम (HDFS), विविध ऍप्लिकेशन्सद्वारे वापरल्या जाणार्या संगणकीय संसाधनांचे व्यवस्थापन करण्याचा मार्ग म्हणून YARN आणि एक एक्झिक्यूशन इंजिन म्हणून मॅपरेड्यूस प्रोग्रामिंग मॉडेलची अंमलबजावणी आहे. ठराविक हडूप अंमलबजावणीमध्ये, स्पार्क, तेझ आणि प्रेस्टो सारखी वेगवेगळी एक्झिक्युशन इंजिने देखील तैनात केली जातात.
स्पार्क हे परस्परसंवादी क्वेरी, मशीन लर्निंग आणि रिअल-टाइम वर्कलोड्सवर केंद्रित एक मुक्त स्रोत फ्रेमवर्क आहे. त्याची स्वतःची स्टोरेज सिस्टम नाही, परंतु HDFS सारख्या इतर स्टोरेज सिस्टमवर किंवा Amazon Redshift, Amazon S3, Couchbase, Cassandra आणि इतर लोकप्रिय स्टोअरवर विश्लेषण चालवते. हडूपवरील स्पार्क इतर हडूप इंजिनांप्रमाणे सामान्य क्लस्टर आणि डेटासेट सामायिक करण्यासाठी यार्नचा फायदा घेते, सेवा आणि प्रतिसादाची सातत्यपूर्ण पातळी सुनिश्चित करते.
Spark unified formula for data read
spark.read.format("jdbc").option("driver","com.mysql.jdbc.Driver")
.option("url","jdbc:mysql://HOST_NAME:PORT_NO/DB_NAME").option("dbtable","TABLE_NAME")
.option("user","USER_NAME").option("password","PASSWORD").load()
Spark unified formula for data write to directory
DATAFRAME.write.format("FILE_FORMAT").partitionBy("category")
.mode("append").save("LOCATION")
Spark unified formula for data write to hive table
DATAFRAME.write.format("FILE_FORMAT").partitionBy("category")
.mode("append").saveAsTable("HIVE_TABLE")