अपाचे स्पार्क क्या है?
अपाचे स्पार्क एक खुला स्रोत, वितरित प्रसंस्करण प्रणाली है जिसका उपयोग बड़े डेटा वर्कलोड के लिए किया जाता है। यह इन-मेमोरी कैशिंग का उपयोग करता है, और किसी भी आकार के डेटा के खिलाफ तेजी से विश्लेषणात्मक प्रश्नों के लिए अनुकूलित क्वेरी निष्पादन का उपयोग करता है। यह जावा, स्काला, पायथन और आर में विकास एपीआई प्रदान करता है, और कई वर्कलोड में कोड के पुन: उपयोग का समर्थन करता है- बैच प्रोसेसिंग, इंटरेक्टिव क्वेरी, रीयल-टाइम एनालिटिक्स, मशीन लर्निंग और ग्राफ प्रोसेसिंग। आप इसे FINRA, Yelp, Zillow, DataXu, Urban Institute और CrowdStrike सहित किसी भी उद्योग के संगठनों द्वारा उपयोग करते हुए पाएंगे। अपाचे स्पार्क सबसे लोकप्रिय बड़े डेटा वितरित प्रसंस्करण ढांचे में से एक बन गया है।अपाचे स्पार्क का इतिहास क्या है?
Apache Spark की शुरुआत 2009 में UC बर्कले के AMPLab में एक शोध परियोजना के रूप में हुई थी, जो डेटा-गहन अनुप्रयोग डोमेन पर केंद्रित छात्रों, शोधकर्ताओं और शिक्षकों को शामिल करने वाला एक सहयोग है। स्पार्क का लक्ष्य Hadoop MapReduce की मापनीयता और दोष सहिष्णुता को बनाए रखते हुए, मशीन सीखने और इंटरैक्टिव डेटा विश्लेषण जैसे तेज़ पुनरावृत्ति प्रसंस्करण के लिए अनुकूलित एक नया ढांचा बनाना था। "स्पार्क: क्लस्टर कंप्यूटिंग विद वर्किंग सेट्स" शीर्षक वाला पहला पेपर जून 2010 में प्रकाशित हुआ था, और स्पार्क को बीएसडी लाइसेंस के तहत ओपन सोर्स किया गया था। जून, 2013 में, स्पार्क ने अपाचे सॉफ्टवेयर फाउंडेशन (एएसएफ) में ऊष्मायन स्थिति में प्रवेश किया, और फरवरी, 2014 में अपाचे टॉप-लेवल प्रोजेक्ट के रूप में स्थापित किया। स्पार्क स्टैंडअलोन, अपाचे मेसोस पर, या अक्सर अपाचे हडोप पर चला सकता है।आज, स्पार्क Hadoop पारिस्थितिकी तंत्र में सबसे सक्रिय परियोजनाओं में से एक बन गया है, जिसमें कई संगठन बड़े डेटा को संसाधित करने के लिए Hadoop के साथ स्पार्क को अपना रहे हैं। 2017 में, स्पार्क के पास 365, 000 मीटअप सदस्य थे, जो दो वर्षों में 5x वृद्धि का प्रतिनिधित्व करता है। इसे 2009 से 200 से अधिक संगठनों के 1,000 से अधिक डेवलपर्स द्वारा योगदान प्राप्त हुआ है।
अपाचे स्पार्क कैसे काम करता है?
Hadoop MapReduce समानांतर, वितरित एल्गोरिथम के साथ बड़े डेटा सेट को संसाधित करने के लिए एक प्रोग्रामिंग मॉडल है। डेवलपर्स काम के वितरण और दोष सहिष्णुता के बारे में चिंता किए बिना बड़े पैमाने पर समानांतर ऑपरेटरों को लिख सकते हैं। हालाँकि, MapReduce के लिए एक चुनौती क्रमिक बहु-चरणीय प्रक्रिया है जो किसी कार्य को चलाने के लिए आवश्यक है। प्रत्येक चरण के साथ, MapReduce क्लस्टर से डेटा पढ़ता है, संचालन करता है, और परिणाम वापस HDFS को लिखता है। चूंकि प्रत्येक चरण में डिस्क को पढ़ने और लिखने की आवश्यकता होती है, इसलिए डिस्क I/O की विलंबता के कारण MapReduce कार्य धीमे होते हैं।मेमोरी में प्रसंस्करण करके, नौकरी में चरणों की संख्या को कम करके, और कई समानांतर संचालन में डेटा का पुन: उपयोग करके, MapReduce की सीमाओं को संबोधित करने के लिए स्पार्क बनाया गया था। स्पार्क के साथ, केवल एक-चरण की आवश्यकता होती है जहां डेटा को मेमोरी में पढ़ा जाता है, संचालन किया जाता है, और परिणाम वापस लिखे जाते हैं - जिसके परिणामस्वरूप बहुत तेज निष्पादन होता है। स्पार्क मशीन लर्निंग एल्गोरिदम को तेज करने के लिए इन-मेमोरी कैश का उपयोग करके डेटा का पुन: उपयोग करता है जो एक ही डेटासेट पर एक फ़ंक्शन को बार-बार कॉल करता है। डेटा का पुन: उपयोग DataFrames के निर्माण के माध्यम से पूरा किया जाता है, रेजिलिएंट डिस्ट्रिब्यूटेड डेटासेट (RDD) पर एक अमूर्तता, जो वस्तुओं का एक संग्रह है जिसे मेमोरी में कैश किया जाता है, और कई स्पार्क संचालन में पुन: उपयोग किया जाता है। यह नाटकीय रूप से विलंबता को कम करता है जिससे स्पार्क को MapReduce की तुलना में कई गुना तेज बनाता है, खासकर मशीन लर्निंग और इंटरेक्टिव एनालिटिक्स करते समय।
अपाचे स्पार्क बनाम अपाचे हडूप
Spark और Hadoop MapReduce के डिज़ाइन में अंतर के अलावा, कई संगठनों ने इन बड़े डेटा फ़्रेमवर्क को एक व्यापक व्यावसायिक चुनौती को हल करने के लिए एक साथ उपयोग करते हुए मानार्थ पाया है।Hadoop एक ओपन सोर्स फ्रेमवर्क है जिसमें स्टोरेज के रूप में Hadoop डिस्ट्रिब्यूटेड फाइल सिस्टम (HDFS), YARN विभिन्न अनुप्रयोगों द्वारा उपयोग किए जाने वाले कंप्यूटिंग संसाधनों के प्रबंधन के तरीके के रूप में, और MapReduce प्रोग्रामिंग मॉडल को एक निष्पादन इंजन के रूप में लागू करता है। एक विशिष्ट Hadoop कार्यान्वयन में, स्पार्क, तेज़ और प्रेस्टो जैसे विभिन्न निष्पादन इंजन भी तैनात किए जाते हैं।
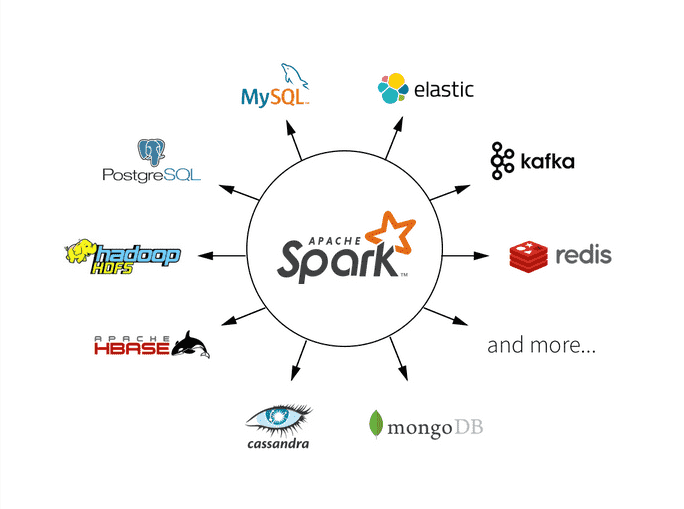
स्पार्क एक ओपन सोर्स फ्रेमवर्क है जो इंटरेक्टिव क्वेरी, मशीन लर्निंग और रीयल-टाइम वर्कलोड पर केंद्रित है। इसका अपना स्टोरेज सिस्टम नहीं है, लेकिन अन्य स्टोरेज सिस्टम जैसे HDFS, या अन्य लोकप्रिय स्टोर जैसे Amazon Redshift, Amazon S3, Couchbase, Cassandra, और अन्य पर एनालिटिक्स चलाता है। Hadoop पर स्पार्क एक सामान्य क्लस्टर और डेटासेट को अन्य Hadoop इंजनों के रूप में साझा करने के लिए YARN का लाभ उठाता है, सेवा के लगातार स्तर और प्रतिक्रिया सुनिश्चित करता है।
Spark unified formula for data read
spark.read.format("jdbc").option("driver","com.mysql.jdbc.Driver")
.option("url","jdbc:mysql://HOST_NAME:PORT_NO/DB_NAME").option("dbtable","TABLE_NAME")
.option("user","USER_NAME").option("password","PASSWORD").load()
Spark unified formula for data write to directory
DATAFRAME.write.format("FILE_FORMAT").partitionBy("category")
.mode("append").save("LOCATION")
Spark unified formula for data write to hive table
DATAFRAME.write.format("FILE_FORMAT").partitionBy("category")
.mode("append").saveAsTable("HIVE_TABLE")