HDFS
एचडीएफएस एक वितरित फाइल सिस्टम है जो कमोडिटी हार्डवेयर पर चलने वाले बड़े डेटा सेट को संभालता है। इसका उपयोग एकल Apache Hadoop क्लस्टर को सैकड़ों (और यहां तक कि हजारों) नोड्स तक स्केल करने के लिए किया जाता है। HDFS Apache Hadoop के प्रमुख घटकों में से एक है, अन्य MapReduce और YARN हैं। एचडीएफएस को अपाचे एचबेस के साथ भ्रमित या प्रतिस्थापित नहीं किया जाना चाहिए, जो एक कॉलम-उन्मुख गैर-संबंधपरक डेटाबेस प्रबंधन प्रणाली है जो एचडीएफएस के शीर्ष पर बैठता है और इसके इन-मेमोरी प्रोसेसिंग इंजन के साथ रीयल-टाइम डेटा आवश्यकताओं का बेहतर समर्थन कर सकता है।
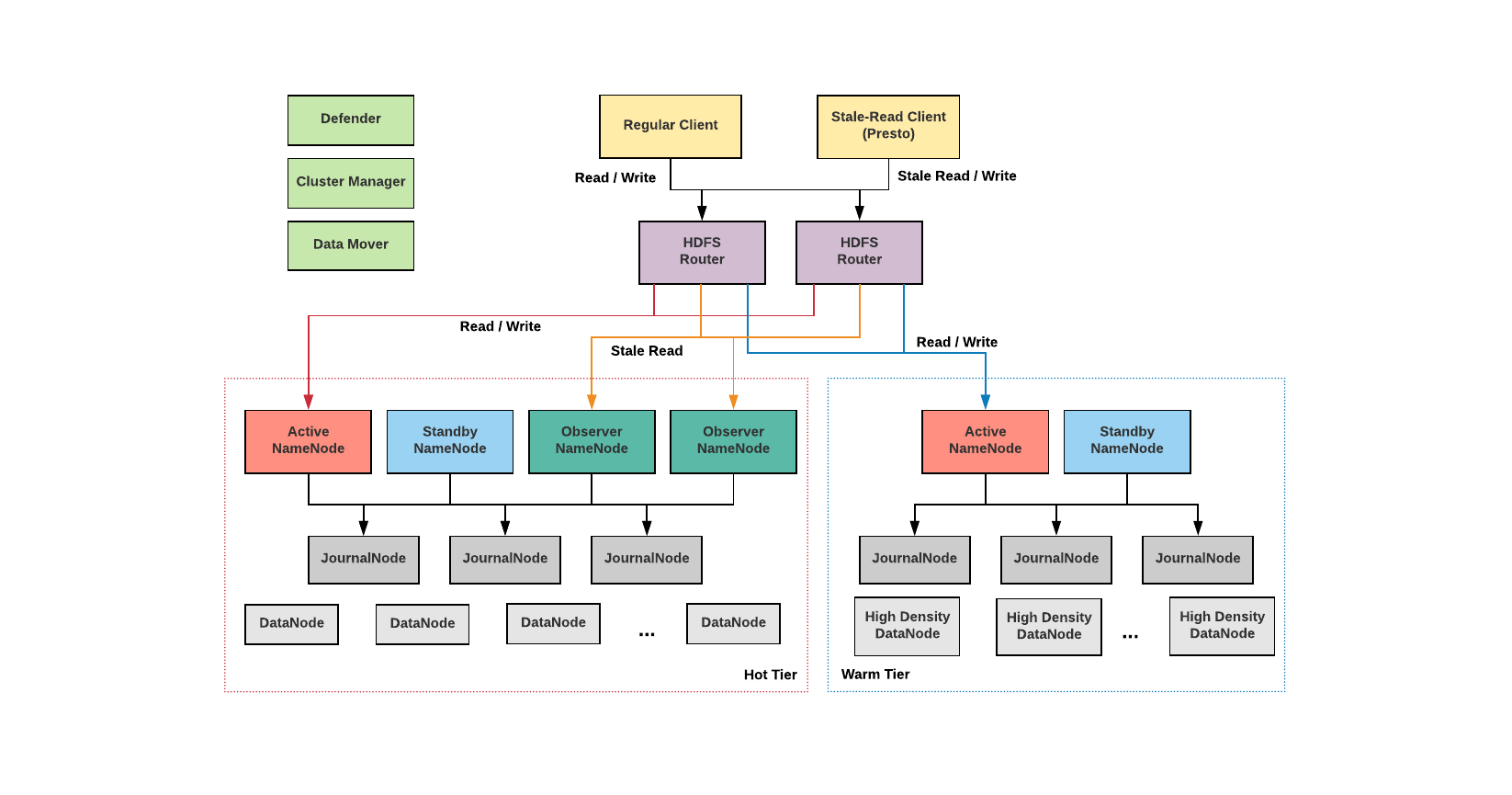
Hadoop डिस्ट्रिब्यूटेड फाइल सिस्टम (HDFS) Hadoop अनुप्रयोगों द्वारा उपयोग किया जाने वाला प्राथमिक डेटा स्टोरेज सिस्टम है। HDFS एक वितरित फ़ाइल सिस्टम को लागू करने के लिए एक NameNode और DataNode आर्किटेक्चर को नियोजित करता है जो अत्यधिक स्केलेबल Hadoop क्लस्टर में डेटा के लिए उच्च-प्रदर्शन पहुँच प्रदान करता है।
Hadoop अपने आप में एक खुला स्रोत वितरित प्रसंस्करण ढांचा है जो बड़े डेटा अनुप्रयोगों के लिए डेटा प्रसंस्करण और भंडारण का प्रबंधन करता है। एचडीएफएस कई हडूप पारिस्थितिकी तंत्र प्रौद्योगिकियों का एक महत्वपूर्ण हिस्सा है। यह बड़े डेटा के पूल के प्रबंधन और संबंधित बड़े डेटा एनालिटिक्स अनुप्रयोगों का समर्थन करने के लिए एक विश्वसनीय साधन प्रदान करता है।
HDFS कैसे काम करता है?
एचडीएफएस कंप्यूट नोड्स के बीच डेटा के तेजी से हस्तांतरण को सक्षम बनाता है। इसकी शुरुआत में, इसे MapReduce के साथ निकटता से जोड़ा गया था, डेटा प्रोसेसिंग के लिए एक ढांचा जो क्लस्टर में नोड्स के बीच काम को फ़िल्टर और विभाजित करता है, और यह परिणामों को एक क्वेरी के समेकित उत्तर में व्यवस्थित और संघनित करता है। इसी तरह, जब एचडीएफएस डेटा लेता है, तो यह जानकारी को अलग-अलग ब्लॉक में तोड़ देता है और उन्हें क्लस्टर में अलग-अलग नोड्स में वितरित करता है।एचडीएफएस के साथ, सर्वर पर डेटा एक बार लिखा जाता है, और उसके बाद कई बार पढ़ा और पुन: उपयोग किया जाता है। HDFS में एक प्राथमिक NameNode होता है, जो इस बात पर नज़र रखता है कि क्लस्टर में फ़ाइल डेटा कहाँ रखा गया है।
HDFS में कमोडिटी हार्डवेयर क्लस्टर पर कई DataNodes भी होते हैं - आमतौर पर क्लस्टर में प्रति नोड एक। डेटा नोड्स आमतौर पर डेटा सेंटर में एक ही रैक के भीतर व्यवस्थित होते हैं। डेटा को अलग-अलग ब्लॉकों में विभाजित किया जाता है और भंडारण के लिए विभिन्न डेटा नोड्स के बीच वितरित किया जाता है। अत्यधिक कुशल समानांतर प्रसंस्करण को सक्षम करते हुए, ब्लॉक को नोड्स में भी दोहराया जाता है।
NameNode जानता है कि कौन से DataNode में कौन से ब्लॉक हैं और मशीन क्लस्टर के भीतर DataNodes कहाँ रहते हैं। NameNode फ़ाइलों तक पहुँच का प्रबंधन भी करता है, जिसमें DataNodes में पढ़ना, लिखना, बनाना, हटाना और डेटा ब्लॉक प्रतिकृति शामिल है।
NameNode DataNodes के साथ मिलकर काम करता है। नतीजतन, क्लस्टर आवश्यकतानुसार नोड्स को जोड़कर या घटाकर वास्तविक समय में सर्वर क्षमता की मांग को गतिशील रूप से अनुकूलित कर सकता है।
DataNodes यह निर्धारित करने के लिए NameNode के साथ निरंतर संचार में हैं कि DataNodes को विशिष्ट कार्यों को पूरा करने की आवश्यकता है या नहीं। नतीजतन, NameNode हमेशा प्रत्येक DataNode की स्थिति से अवगत होता है। यदि NameNode को पता चलता है कि एक DataNode ठीक से काम नहीं कर रहा है, तो वह तुरंत उस DataNode के कार्य को उसी डेटा ब्लॉक वाले एक अलग नोड को फिर से सौंप सकता है। DataNodes एक दूसरे के साथ संचार भी करते हैं, जो उन्हें सामान्य फ़ाइल संचालन के दौरान सहयोग करने में सक्षम बनाता है।
इसके अलावा, एचडीएफएस को अत्यधिक दोष-सहिष्णु होने के लिए डिज़ाइन किया गया है। फ़ाइल सिस्टम डेटा के प्रत्येक टुकड़े को कई बार दोहराता है - या प्रतिलिपि बनाता है और प्रतियों को अलग-अलग नोड्स में वितरित करता है, अन्य प्रतियों की तुलना में एक अलग सर्वर रैक पर कम से कम एक प्रति रखता है।
HDFS आर्किटेक्चर, NameNodes और DataNodes एचडीएफएस प्राथमिक/द्वितीयक आर्किटेक्चर का उपयोग करता है। एचडीएफएस क्लस्टर का नामेनोड प्राथमिक सर्वर है जो फाइल सिस्टम नेमस्पेस का प्रबंधन करता है और फाइलों तक क्लाइंट एक्सेस को नियंत्रित करता है। Hadoop डिस्ट्रीब्यूटेड फाइल सिस्टम के केंद्रीय घटक के रूप में, NameNode फाइल सिस्टम नेमस्पेस का रखरखाव और प्रबंधन करता है और क्लाइंट को सही एक्सेस अनुमतियां प्रदान करता है। सिस्टम के DataNodes उस स्टोरेज का प्रबंधन करते हैं जो उनके द्वारा चलाए जाने वाले नोड्स से जुड़ा होता है।
एचडीएफएस एक फाइल सिस्टम नेमस्पेस को उजागर करता है और उपयोगकर्ता डेटा को फाइलों में संग्रहीत करने में सक्षम बनाता है। एक फ़ाइल को एक या अधिक ब्लॉकों में विभाजित किया जाता है जो DataNodes के एक सेट में संग्रहीत होते हैं। NameNode फाइल सिस्टम नेमस्पेस ऑपरेशन करता है, जिसमें फाइलों और निर्देशिकाओं को खोलना, बंद करना और नाम बदलना शामिल है। NameNode DataNodes के लिए ब्लॉक मैपिंग को भी नियंत्रित करता है। DataNodes फ़ाइल सिस्टम के क्लाइंट से पढ़ने और लिखने के अनुरोधों की सेवा करता है। इसके अलावा, जब NameNode उन्हें ऐसा करने का निर्देश देता है, तो वे ब्लॉक निर्माण, विलोपन और प्रतिकृति करते हैं।
एचडीएफएस पारंपरिक पदानुक्रमित फ़ाइल संगठन का समर्थन करता है। कोई एप्लिकेशन या उपयोगकर्ता निर्देशिका बना सकता है और फिर इन निर्देशिकाओं के अंदर फ़ाइलों को संग्रहीत कर सकता है। फ़ाइल सिस्टम नेमस्पेस पदानुक्रम अधिकांश अन्य फ़ाइल सिस्टमों की तरह है -- एक उपयोगकर्ता फ़ाइलों को एक निर्देशिका से दूसरी निर्देशिका में बना सकता है, हटा सकता है, नाम बदल सकता है या स्थानांतरित कर सकता है।
NameNode फ़ाइल सिस्टम नाम स्थान या उसके गुणों में किसी भी परिवर्तन को रिकॉर्ड करता है। एक एप्लिकेशन एक फाइल की प्रतिकृतियों की संख्या निर्धारित कर सकता है जिसे एचडीएफएस को बनाए रखना चाहिए। NameNode फ़ाइल की प्रतियों की संख्या को संग्रहीत करता है, जिसे उस फ़ाइल का प्रतिकृति कारक कहा जाता है।
HDFS की विशेषताएं
ऐसी कई विशेषताएं हैं जो एचडीएफएस को विशेष रूप से उपयोगी बनाती हैं, जिनमें शामिल हैं:डेटा प्रतिकृति। इसका उपयोग यह सुनिश्चित करने के लिए किया जाता है कि डेटा हमेशा उपलब्ध है और डेटा हानि को रोकता है। उदाहरण के लिए, जब कोई नोड क्रैश हो जाता है या कोई हार्डवेयर विफलता होती है, तो प्रतिकृति डेटा को क्लस्टर के भीतर कहीं और से खींचा जा सकता है, इसलिए डेटा पुनर्प्राप्त होने पर प्रसंस्करण जारी रहता है। दोष सहिष्णुता और विश्वसनीयता। एचडीएफएस की फाइल ब्लॉक को दोहराने और एक बड़े क्लस्टर में नोड्स में स्टोर करने की क्षमता गलती सहनशीलता और विश्वसनीयता सुनिश्चित करती है। उच्च उपलब्धता। जैसा कि पहले उल्लेख किया गया है, नोटों में प्रतिकृति के कारण, डेटा उपलब्ध है, भले ही NameNode या DataNode विफल हो। मापनीयता। चूंकि एचडीएफएस क्लस्टर में विभिन्न नोड्स पर डेटा संग्रहीत करता है, जैसे-जैसे आवश्यकताएं बढ़ती हैं, क्लस्टर सैकड़ों नोड्स तक स्केल कर सकता है। उच्च थ्रूपुट। चूंकि एचडीएफएस डेटा को वितरित तरीके से संग्रहीत करता है, इसलिए डेटा को नोड्स के क्लस्टर पर समानांतर में संसाधित किया जा सकता है। यह, प्लस डेटा लोकैलिटी (अगला बुलेट देखें), प्रसंस्करण समय में कटौती करता है और उच्च थ्रूपुट को सक्षम करता है। डेटा इलाके। एचडीएफएस के साथ, डेटा नोड्स पर गणना होती है जहां डेटा रहता है, डेटा को कम्प्यूटेशनल यूनिट में स्थानांतरित करने के बजाय। डेटा और कंप्यूटिंग प्रक्रिया के बीच की दूरी को कम करके, यह दृष्टिकोण नेटवर्क की भीड़ को कम करता है और सिस्टम के समग्र थ्रूपुट को बढ़ाता है। एचडीएफएस का उपयोग करने के क्या लाभ हैं? एचडीएफएस का उपयोग करने के पांच मुख्य लाभ हैं, जिनमें शामिल हैं:
लागत प्रभावशीलता। डेटा को स्टोर करने वाले डेटानोड्स सस्ते ऑफ-द-शेल्फ हार्डवेयर पर भरोसा करते हैं, जो भंडारण लागत में कटौती करता है। साथ ही, चूंकि एचडीएफएस खुला स्रोत है, इसलिए कोई लाइसेंस शुल्क नहीं है। बड़ा डेटा सेट भंडारण। एचडीएफएस किसी भी आकार के विभिन्न प्रकार के डेटा को स्टोर करता है - मेगाबाइट से पेटाबाइट तक - और संरचित और असंरचित डेटा सहित किसी भी प्रारूप में। हार्डवेयर विफलता से तेजी से वसूली। HDFS को दोषों का पता लगाने और अपने आप ठीक होने के लिए डिज़ाइन किया गया है। सुवाह्यता। एचडीएफएस सभी हार्डवेयर प्लेटफॉर्म पर पोर्टेबल है, और यह विंडोज, लिनक्स और मैक ओएस/एक्स सहित कई ऑपरेटिंग सिस्टम के साथ संगत है। स्ट्रीमिंग डेटा एक्सेस। एचडीएफएस उच्च डेटा थ्रूपुट के लिए बनाया गया है, जो स्ट्रीमिंग डेटा तक पहुंच के लिए सबसे अच्छा है। बड़े डेटा प्रबंधन पर अधिक Hadoop बड़े डेटा प्रबंधन का एक महत्वपूर्ण हिस्सा है, लेकिन यह एकमात्र पहलू नहीं है जिसके बारे में डेटा प्रबंधकों को पता होना चाहिए। पूरी तस्वीर प्राप्त करें:
बड़े डेटा परिवेशों के लिए डेटा गवर्नेंस पर 6 सर्वोत्तम अभ्यास बड़े डेटा विकास को चलाने वाले 5 रुझान Hadoop डिस्ट्रीब्यूटेड फाइल सिस्टम बड़े डेटा से निपटने में मदद करता है एचडीएफएस मामलों और उदाहरणों का उपयोग करता है Hadoop डिस्ट्रिब्यूटेड फाइल सिस्टम Yahoo में उस कंपनी के ऑनलाइन विज्ञापन प्लेसमेंट और खोज इंजन आवश्यकताओं के एक भाग के रूप में उभरा। अन्य वेब-आधारित कंपनियों की तरह, याहू ने कई तरह के अनुप्रयोगों को जोड़ दिया, जो कि अधिक से अधिक डेटा बनाने वाले उपयोगकर्ताओं की बढ़ती संख्या द्वारा एक्सेस किए गए थे।
ईबे, फेसबुक, लिंक्डइन और ट्विटर उन कंपनियों में शामिल हैं, जिन्होंने याहू की तरह की जरूरतों को पूरा करने के लिए बड़े डेटा एनालिटिक्स को रेखांकित करने के लिए एचडीएफएस का इस्तेमाल किया।
HDFS ने विज्ञापन प्रस्तुतिकरण और खोज इंजन आवश्यकताओं को पूरा करने से परे उपयोग पाया है। न्यूयॉर्क टाइम्स ने इसे बड़े पैमाने पर छवि रूपांतरण, लॉग प्रोसेसिंग और मशीन लर्निंग के लिए Media6Degrees, लॉग स्टोरेज और ऑड्स विश्लेषण के लिए LiveBet, सत्र विश्लेषण के लिए Joost, और लॉग विश्लेषण और डेटा माइनिंग के लिए Fox Audience Network के हिस्से के रूप में इस्तेमाल किया। एचडीएफएस कई ओपन सोर्स डेटा लेक के मूल में भी है।
आम तौर पर, कई उद्योगों में कंपनियां बड़े डेटा के पूल का प्रबंधन करने के लिए एचडीएफएस का उपयोग करती हैं, जिनमें शामिल हैं:
इलेक्ट्रिक कंपनियां। बिजली उद्योग स्मार्ट ग्रिड के स्वास्थ्य की निगरानी के लिए अपने पूरे ट्रांसमिशन नेटवर्क में फेजर माप इकाइयों (पीएमयू) को तैनात करता है। ये हाई-स्पीड सेंसर चयनित ट्रांसमिशन स्टेशनों पर आयाम और चरण द्वारा वर्तमान और वोल्टेज को मापते हैं। ये कंपनियां नेटवर्क सेगमेंट में सिस्टम की खराबी का पता लगाने के लिए पीएमयू डेटा का विश्लेषण करती हैं और उसके अनुसार ग्रिड को एडजस्ट करती हैं। उदाहरण के लिए, वे बैकअप पावर स्रोत पर स्विच कर सकते हैं या लोड समायोजन कर सकते हैं। पीएमयू नेटवर्क प्रति सेकंड हजारों रिकॉर्ड देखता है, और इसके परिणामस्वरूप, बिजली कंपनियां सस्ती, अत्यधिक उपलब्ध फाइल सिस्टम, जैसे एचडीएफएस से लाभ उठा सकती हैं। विपणन। लक्षित विपणन अभियान अपने लक्षित दर्शकों के बारे में बहुत कुछ जानने वाले विपणक पर निर्भर करते हैं। विपणक यह जानकारी कई स्रोतों से प्राप्त कर सकते हैं, जिनमें सीआरएम सिस्टम, डायरेक्ट मेल प्रतिक्रियाएं, पॉइंट-ऑफ-सेल सिस्टम, फेसबुक और ट्विटर शामिल हैं। चूंकि इस डेटा का अधिकांश भाग असंरचित है, इसलिए विश्लेषण करने से पहले डेटा डालने के लिए HDFS क्लस्टर सबसे अधिक लागत प्रभावी स्थान है। तेल और गैस प्रदाता। तेल और गैस कंपनियां वीडियो, 3D अर्थ मॉडल और मशीन सेंसर डेटा सहित बहुत बड़े डेटा सेट के साथ विभिन्न प्रकार के डेटा स्वरूपों से निपटती हैं। एक एचडीएफएस क्लस्टर बड़े डेटा विश्लेषण के लिए एक उपयुक्त मंच प्रदान कर सकता है जिसकी आवश्यकता है। शोध करना। डेटा का विश्लेषण अनुसंधान का एक महत्वपूर्ण हिस्सा है, इसलिए, यहां फिर से, एचडीएफएस क्लस्टर बड़ी मात्रा में डेटा को स्टोर करने, संसाधित करने और विश्लेषण करने के लिए एक लागत प्रभावी तरीका प्रदान करते हैं। एचडीएफएस डेटा प्रतिकृति डेटा प्रतिकृति एचडीएफएस प्रारूप का एक महत्वपूर्ण हिस्सा है क्योंकि यह सुनिश्चित करता है कि नोड या हार्डवेयर विफलता होने पर डेटा उपलब्ध रहे। जैसा कि पहले उल्लेख किया गया है, डेटा को ब्लॉक में विभाजित किया जाता है और क्लस्टर में कई नोड्स में दोहराया जाता है। इसलिए, जब एक नोड नीचे चला जाता है, तो उपयोगकर्ता अन्य मशीनों से उस नोड पर मौजूद डेटा तक पहुंच सकता है। एचडीएफएस नियमित अंतराल पर प्रतिकृति प्रक्रिया को बनाए रखता है।