SQOOP
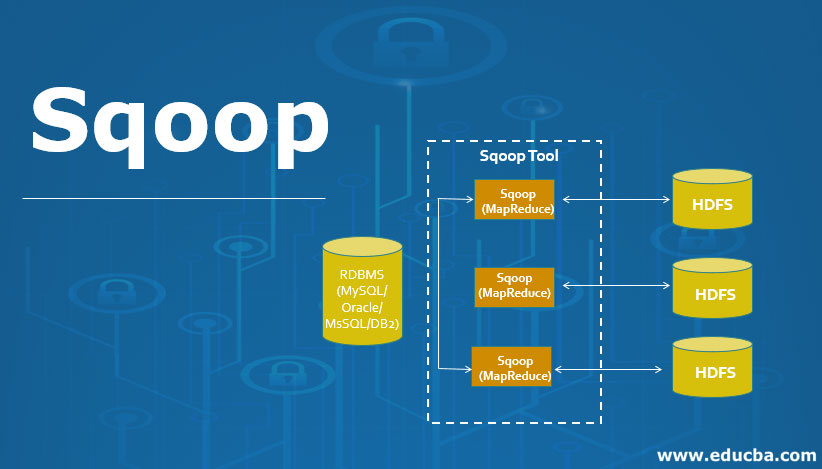
Apache Sqoop Hadoop पारिस्थितिकी तंत्र का हिस्सा है। चूंकि बहुत सारे डेटा को रिलेशनल डेटाबेस सिस्टम से Hadoop पर स्थानांतरित किया जाना था, इसलिए इस कार्य को तेजी से करने के लिए एक समर्पित टूल की आवश्यकता थी। यह वह जगह है जहां Apache Sqoop तस्वीर में आया था जो अब बड़े पैमाने पर RDBMS फ़ाइलों से डेटा को MapReduce प्रसंस्करण के लिए Hadoop पारिस्थितिकी तंत्र में स्थानांतरित करने के लिए उपयोग किया जाता है।
जब डेटा ट्रांसफर करने की बात आती है, तो कुछ निश्चित आवश्यकताओं का ध्यान रखना होता है। इसमें निम्नलिखित शामिल हैं: डेटा में एकरूपता होनी चाहिए; इसे डाउनस्ट्रीम पाइपलाइन के प्रावधान के लिए तैयार किया जाना चाहिए, और उपयोगकर्ताओं को उत्पादन प्रणाली संसाधनों की खपत सुनिश्चित करनी चाहिए; अन्य बातों के अलावा। MapReduce एप्लिकेशन बाहरी रिलेशनल डेटाबेस में रहने वाले डेटा को सीधे एक्सेस करने में सक्षम नहीं है। यह विधि सिस्टम को क्लस्टर नोड्स से बहुत अधिक लोड उत्पन्न करने के जोखिम के लिए उजागर कर सकती है।
SQOOP :
पहले जब कोई Hadoop नहीं था या उस समय बड़े डेटा की कोई अवधारणा नहीं थी, उस समय सभी डेटा का उपयोग रिलेशनल डेटाबेस प्रबंधन प्रणाली में संग्रहीत करने के लिए किया जाता है। लेकिन आजकल बिग डेटा की अवधारणा के आने के बाद, डेटा को अधिक संक्षिप्त और प्रभावी तरीके से संग्रहीत करने की आवश्यकता है। इस प्रकार स्कूप अस्तित्व में आता है।
इसलिए सभी डेटा जो एक रिलेशनल डेटाबेस मैनेजमेंट सिस्टम में संग्रहीत हैं, उन्हें Hadoop संरचना में स्थानांतरित करने की आवश्यकता है। इसलिए इतनी बड़ी मात्रा में डेटा को मैन्युअल रूप से स्थानांतरित करना संभव नहीं है, लेकिन स्कूप की मदद से हम इसे करने में सक्षम हैं। इस प्रकार Sqoop को उस उपकरण के रूप में परिभाषित किया गया है जिसका उपयोग संबंधपरक डेटाबेस प्रबंधन प्रणाली से Hadoop सर्वर में डेटा स्थानांतरण संचालन करने के लिए किया जाता है। इस प्रकार यह बड़े पैमाने पर डेटा को स्रोत के एक बिंदु से दूसरे स्रोत तक स्थानांतरित करने में मदद करता है।
स्कूप की कुछ महत्वपूर्ण विशेषताएं:
Sqoop हमें SQL क्वेरी के परिणाम को Hadoop वितरित फ़ाइल सिस्टम में जोड़ने में भी मदद करता है। Sqoop हमें संसाधित डेटा को सीधे हाइव या Hbase में लोड करने में मदद करता है। यह Kerberos की मदद से डेटा का सुरक्षा संचालन करता है। Sqoop की मदद से हम प्रोसेस्ड डेटा का कंप्रेशन कर सकते हैं। स्कूप प्रकृति में अत्यधिक शक्तिशाली और कुशल है। स्कूप में दो प्रमुख ऑपरेशन किए जाते हैं:
आयात करें
निर्यात करें
मूल रूप से स्कूप में होने वाले ऑपरेशन आमतौर पर उपयोगकर्ता के अनुकूल होते हैं। Sqoop ने उपयोगकर्ता के आदेश को संसाधित करने के लिए कमांड-लाइन इंटरफ़ेस का उपयोग किया। उपयोगकर्ता के साथ बातचीत करने के लिए जावा एपीआई का उपयोग करके स्कूप वैकल्पिक तरीकों का भी उपयोग कर सकता है। मूल रूप से, जब यह उपयोगकर्ता द्वारा कमांड प्राप्त करता है, तो इसे स्कूप द्वारा नियंत्रित किया जाता है और फिर कमांड की आगे की प्रक्रिया होती है। Sqoop केवल उपयोगकर्ता के आदेश के आधार पर डेटा का आयात और निर्यात करने में सक्षम होगा, यह डेटा का एकत्रीकरण बनाने में सक्षम नहीं है।
Sqoop एक उपकरण है जिसमें निम्नलिखित तरीके से काम करता है, यह पहले तर्क को पार्स करता है जो उपयोगकर्ता द्वारा कमांड-लाइन इंटरफ़ेस में प्रदान किया जाता है और फिर उन तर्कों को एक और चरण में भेजता है जहां तर्क केवल मानचित्र कार्य के लिए प्रेरित होते हैं। एक बार जब नक्शा तर्क प्राप्त कर लेता है तो यह कमांड लाइन इंटरफेस में एक तर्क के रूप में उपयोगकर्ता द्वारा परिभाषित संख्या के आधार पर कई मैपर जारी करने का आदेश देता है। एक बार जब ये नौकरियां आयात कमांड के लिए होती हैं, तो प्रत्येक मैपर कार्य को डेटा के संबंधित हिस्से के साथ सौंपा जाता है जिसे कुंजी के आधार पर आयात किया जाना है जिसे उपयोगकर्ता द्वारा कमांड लाइन इंटरफ़ेस में परिभाषित किया जाता है। प्रक्रिया की दक्षता बढ़ाने के लिए Sqoop समानांतर प्रसंस्करण तकनीक का उपयोग करता है जिसमें डेटा सभी मैपर के बीच समान रूप से वितरित किया जाता है। इसके बाद, प्रत्येक मैपर जावा डेटाबेस कनेक्शन मॉडल का उपयोग करके डेटाबेस के साथ एक व्यक्तिगत कनेक्शन बनाता है और फिर Sqoop द्वारा निर्दिष्ट डेटा के अलग-अलग हिस्से को प्राप्त करता है। एक बार डेटा प्राप्त हो जाने के बाद डेटा को कमांड लाइन में दिए गए तर्क के आधार पर एचडीएफएस या एचबेस या हाइव में लिखा जाता है। इस प्रकार Sqoop आयात की प्रक्रिया पूरी हो गई है।
Sqoop में डेटा की निर्यात प्रक्रिया उसी तरह से की जाती है, Sqoop निर्यात उपकरण जो उपलब्ध है, Hadoop वितरित सिस्टम से रिलेशनल डेटाबेस प्रबंधन प्रणाली में फ़ाइलों के सेट की अनुमति देकर ऑपरेशन करता है। आयात प्रक्रिया के दौरान इनपुट के रूप में दी गई फाइलों को रिकॉर्ड कहा जाता है, उसके बाद जब उपयोगकर्ता अपना काम सबमिट करता है तो इसे मैप टास्क में मैप किया जाता है जो डेटा की फाइलों को हडूप डेटा स्टोरेज से लाता है, और इन डेटा फाइलों को किसी भी संरचित डेटा में निर्यात किया जाता है। गंतव्य जो संबंधपरक डेटाबेस प्रबंधन प्रणाली जैसे MySQL, SQL सर्वर, और Oracle, आदि के रूप में है।
आइए अब हम दो मुख्य कार्यों को विस्तार से समझते हैं:
Sqoop Import :
स्कूप इंपोर्ट कमांड ऑपरेशन के कार्यान्वयन में मदद करता है। इंपोर्ट कमांड की मदद से हम रिलेशनल डेटाबेस मैनेजमेंट सिस्टम से Hadoop डेटाबेस सर्वर पर एक टेबल इम्पोर्ट कर सकते हैं। Hadoop संरचना में रिकॉर्ड्स को टेक्स्ट फाइलों में संग्रहीत किया जाता है और प्रत्येक रिकॉर्ड को Hadoop डेटाबेस सर्वर में एक अलग रिकॉर्ड के रूप में आयात किया जाता है। हम डेटा आयात करते समय हाइव में लोड और विभाजन भी बना सकते हैं..Sqoop डेटा के वृद्धिशील आयात का भी समर्थन करता है जिसका अर्थ है कि यदि हमने डेटाबेस आयात किया है और हम कुछ और पंक्तियां जोड़ना चाहते हैं, तो इन कार्यों की सहायता से हम केवल जोड़ सकते हैं मौजूदा डेटाबेस में नई पंक्तियाँ, संपूर्ण डेटाबेस नहीं।
Normal Import
sqoop import --connect jdbc:mysql://HOST_NAME/DB_NAME --username USER_NAME -password PASSWORD -m 1 --table TABLE_NAME --delete-target-dir --target-dir TARGET_DIRControlling Import(where)
sqoop import --connect jdbc:mysql://HOST_NAME/DB_NAME --username USER_NAME -password PASSWORD -m 1 --table TABLE_NAME --where "WHERE CONDITION" --delete-target-dir --target-dir TARGET_DIRControlling Import(query)
sqoop import --connect jdbc:mysql://HOST_NAME/DB_NAME --username USER_NAME -password PASSWORD -m 1 --query "sql_query_where WHERE \$CONDITIONS" --delete-target-dir --target-dir TARGET_DIRIncermental(append)
sqoop import --connect jdbc:mysql://HOST_NAME/DB_NAME --username USER_NAME -password PASSWORD -m 1 --table TABLE_NAME --incermental append --check-column COLUMN_NAME --last-value LAST_VALUE --delete-target-dir --target-dir TARGET_DIRIncermental(lastmodified)
sqoop import --connect jdbc:mysql://HOST_NAME/DB_NAME --username USER_NAME -password PASSWORD -m 1 --table TABLE_NAME --incermental lastmodified --check-column COLUMN_NAME --last-value LAST_VALUE --merge-key COLUMN_NAME --delete-target-dir --target-dir TARGET_DIRNormal Import as parquetfile
sqoop import --connect jdbc:mysql://HOST_NAME/DB_NAME --username USER_NAME -password PASSWORD -m 1 --table TABLE_NAME --delete-target-dir --target-dir TARGET_DIR --as-parquetfileNormal Import as avrofile
sqoop import --connect jdbc:mysql://HOST_NAME/DB_NAME --username USER_NAME -password PASSWORD -m 1 --table TABLE_NAME --delete-target-dir --target-dir TARGET_DIR --as-avrodatafileNormal Import default format text
sqoop import --connect jdbc:mysql://HOST_NAME/DB_NAME --username USER_NAME -password PASSWORD -m 1 --table TABLE_NAME --delete-target-dir --target-dir TARGET_DIR --as-textfileNormal Import --as-textfile
sqoop import --connect jdbc:mysql://HOST_NAME/DB_NAME --username USER_NAME -password PASSWORD -m 1 --table TABLE_NAME --delete-target-dir --target-dir TARGET_DIR --as-textfilecreateScoop job
scoop job --create sc_job --import --connect jdbc:mysql://HOST_NAME/DB_NAME --username USER_NAME -password PASSWORD -m 1 --table TABLE_NAME --delete-target-dir --target-dir TARGET_DIRimport all table
sqoop import-all-tables --connect mysql://host/dbname --username --password --warehouse-dir /user/cloudera/all_table --exclude customer8,customer9,customer10Sqoop Export :
Sqoop with AWS s3(form s3 to local db)
sqoop export -Dfs.s3a.access.key=ACCESS_KEY -Dfs.s3a.secret.key=SECRET_KEY -Dfs.s3a.endpoint=URL --connect jdbc:mysql://HOST_NAME/DB_NAME --username USER_NAME -password PASSWORD -m 1 --table TABLE_NAME --export-dir TARGET_S3a_DIRSqoop export
sqoop export --connect jdbc:mysql://HOST_NAME/DB_NAME --username USER_NAME -password PASSWORD -m 1 --table TABLE_NAME --export-dir SOURCE_DIRSqoop multi threading Normal Import with multi mapper (-m 4)
sqoop import --connect jdbc:mysql://HOST_NAME/DB_NAME --username USER_NAME -password PASSWORD -m 4 --split-by COLUMN_NAME --table TABLE_NAME --delete-target-dir --target-dir TARGET_DIRSqoop export with staging table for remove db lass
sqoop export --connect jdbc:mysql://HOST_NAME/DB_NAME --username USER_NAME -password PASSWORD -m 1 --staging-table STAGING_TABLE_NAME --table TABLE_NAME --delete-target-dir --export-dir SOURCE_DIR1)sqoop.export.records per statement
- यह प्रत्येक सम्मिलन कथन में उपयोग की जाने वाली पंक्तियों की संख्या निर्दिष्ट करना है।2)sqoop.export.statements.per.transaction
- We can determine how many insert statements will be issued on the database prior to commit transactionsqoop export
-sqoop.export.records.per.statement=3 --connect jdbc:mysql://HOST_NAME/DB_NAME --username USER_NAME -password PASSWORD -m 1 --staging-table STAGING_TABLE_NAME --table TABLE_NAME --delete-target-dir --export-dir SOURCE_DIRgoto 3 insert statement(per row) to hive default value is 100
sqoop export -sqoop.export.records.per.transaction=2 --connect jdbc:mysql://HOST_NAME/DB_NAME --username USER_NAME -password PASSWORD -m 1 --staging-table STAGING_TABLE_NAME --table TABLE_NAME --delete-target-dir --export-dir SOURCE_DIRस्कूप एक्सपोर्ट कमांड ऑपरेशन के कार्यान्वयन में मदद करता है। निर्यात कमांड की मदद से जो ऑपरेशन की रिवर्स प्रक्रिया के रूप में काम करता है। इसके साथ निर्यात कमांड की मदद से हम डेटा को हडूप डेटाबेस फाइल सिस्टम से रिलेशनल डेटाबेस मैनेजमेंट सिस्टम में स्थानांतरित कर सकते हैं। निर्यात किया जाने वाला डेटा ऑपरेशन पूरा होने से पहले रिकॉर्ड में संसाधित किया जाता है। डेटा का निर्यात दो चरणों के साथ किया जाता है, पहला मेटाडेटा के लिए डेटाबेस की जांच करना और दूसरे चरण में डेटा का माइग्रेशन शामिल है।
यहां आप अंदाजा लगा सकते हैं कि स्कूप की मदद से हडूप में आयात और निर्यात कैसे किया जाता है।
स्कूप के लाभ:
Sqoop की मदद से, हम Oracle, Teradata, आदि जैसे विभिन्न संरचित डेटा स्टोर के साथ डेटा का स्थानांतरण संचालन कर सकते हैं। Sqoop हमें बहुत तेज़ और लागत प्रभावी तरीके से ETL संचालन करने में मदद करता है। स्कूप की मदद से, हम डेटा की समानांतर प्रोसेसिंग कर सकते हैं जिससे समग्र प्रक्रिया तेज हो जाती है। Sqoop अपने संचालन के लिए MapReduce तंत्र का उपयोग करता है जो दोष सहिष्णुता का भी समर्थन करता है।
स्कूप के नुकसान:
विफलता तब होती है जब ऑपरेशन के कार्यान्वयन के लिए समस्या को संभालने के लिए एक विशेष समाधान की आवश्यकता होती है। Sqoop JDBC कनेक्शन का उपयोग रिलेशनल डेटाबेस मैनेजमेंट सिस्टम के साथ संबंध स्थापित करने के लिए करता है जो एक अक्षम तरीका है। स्कूप एक्सपोर्ट ऑपरेशन का प्रदर्शन हार्डवेयर कॉन्फ़िगरेशन रिलेशनल डेटाबेस मैनेजमेंट सिस्टम पर निर्भर करता है।