SQOOP
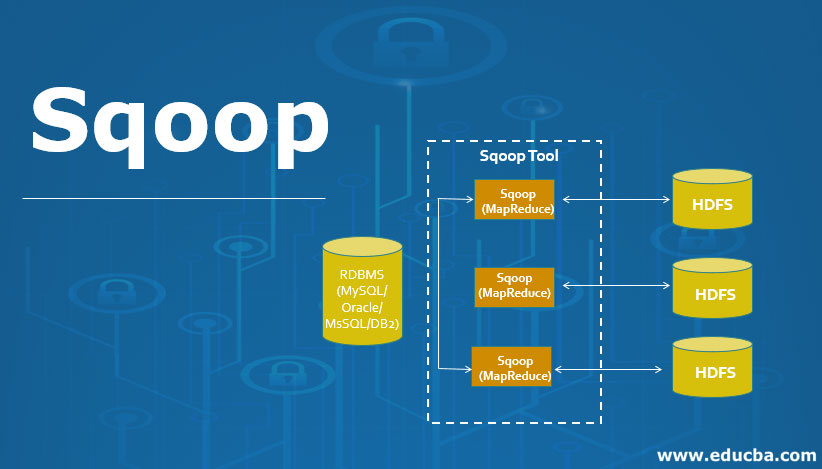
Apache Sqoop is part of the Hadoop ecosystem. Since a lot of the data had to be transferred from relational database systems onto Hadoop, there was a need for a dedicated tool to do this task fast. This is where Apache Sqoop came into the picture which is now extensively used for transferring data from RDBMS files to the Hadoop ecosystem for MapReduce processing and so on.
When it comes to transferring data, there is a certain set of requirements to be taken care of. It includes the following: Data has to have consistency; it should be prepared for provisioning the downstream pipeline, and the users should ensure the consumption of production system resources; among other things. The MapReduce application is not able to directly access the data that is residing in external relational databases. This method can expose the system to the risk of too much load generation from the cluster nodes.
SQOOP :
Previously when there was no Hadoop or there was no concept of big data at that point in time all the data is used to be stored in the relational database management system. But nowadays after the introduction of concepts of Big data, the data need to be stored in a more concise and effective way. Thus Sqoop comes into existence.
So all the data which are stored in a relational database management system needed to be transferred into the Hadoop structure. So the transfer of this large amount of data manually is not possible but with the help of Sqoop, we can able to do it. Thus Sqoop is defined as the tool which is used to perform data transfer operations from relational database management system to Hadoop server. Thus it helps in transfer of bulk of data from one point of source to another point of source.
Some of the important Features of the Sqoop :
Sqoop also helps us to connect the result from the SQL Queries into Hadoop distributed file system. Sqoop helps us to load the processed data directly into the hive or Hbase. It performs the security operation of data with the help of Kerberos. With the help of Sqoop, we can perform compression of processed data. Sqoop is highly powerful and efficient in nature. There are two major operations performed in Sqoop :
Import
Export
Basically the operations that take place in Sqoop are usually user-friendly. Sqoop used the command-line interface to process command of user. The Sqoop can also use alternative ways by using Java APIs to interact with the user. Basically, when it receives command by the user, it is handled by the Sqoop and then the further processing of the command takes place. Sqoop will only be able to perform the import and export of data based on user command it is not able to form an aggregation of data.
Sqoop is a tool in which works in the following manner, it first parses argument which is provided by user in the command-line interface and then sends those arguments to a further stage where arguments are induced for Map only job. Once the Map receives arguments it then gives command of release of multiple mappers depending upon the number defined by the user as an argument in command line Interface. Once these jobs are then for Import command, each mapper task is assigned with respective part of data that is to be imported on basis of key which is defined by user in the command line interface. To increase efficiency of process Sqoop uses parallel processing technique in which data is been distributed equally among all mappers. After this, each mapper then creates an individual connection with the database by using java database connection model and then fetches individual part of the data assigned by Sqoop. Once the data is been fetched then the data is been written in HDFS or Hbase or Hive on basis of argument provided in command line. thus the process Sqoop import is completed.
The export process of the data in Sqoop is performed in same way, Sqoop export tool which available performs the operation by allowing set of files from the Hadoop distributed system back to the Relational Database management system. The files which are given as an input during import process are called records, after that when user submits its job then it is mapped into Map Task that brings the files of data from Hadoop data storage, and these data files are exported to any structured data destination which is in the form of relational database management system such as MySQL, SQL Server, and Oracle, etc.
Let us now understand the two main operations in detail:
Sqoop Import :
Sqoop import command helps in implementation of the operation. With the help of the import command, we can import a table from the Relational database management system to the Hadoop database server. Records in Hadoop structure are stored in text files and each record is imported as a separate record in Hadoop database server. We can also create load and partition in Hive while importing data..Sqoop also supports incremental import of data which means in case we have imported a database and we want to add some more rows, so with the help of these functions we can only add the new rows to existing database, not the complete database.
Normal Import
sqoop import --connect jdbc:mysql://HOST_NAME/DB_NAME --username USER_NAME -password PASSWORD -m 1 --table TABLE_NAME --delete-target-dir --target-dir TARGET_DIRControlling Import(where)
sqoop import --connect jdbc:mysql://HOST_NAME/DB_NAME --username USER_NAME -password PASSWORD -m 1 --table TABLE_NAME --where "WHERE CONDITION" --delete-target-dir --target-dir TARGET_DIRControlling Import(query)
sqoop import --connect jdbc:mysql://HOST_NAME/DB_NAME --username USER_NAME -password PASSWORD -m 1 --query "sql_query_where WHERE \$CONDITIONS" --delete-target-dir --target-dir TARGET_DIRIncermental(append)
sqoop import --connect jdbc:mysql://HOST_NAME/DB_NAME --username USER_NAME -password PASSWORD -m 1 --table TABLE_NAME --incermental append --check-column COLUMN_NAME --last-value LAST_VALUE --delete-target-dir --target-dir TARGET_DIRIncermental(lastmodified)
sqoop import --connect jdbc:mysql://HOST_NAME/DB_NAME --username USER_NAME -password PASSWORD -m 1 --table TABLE_NAME --incermental lastmodified --check-column COLUMN_NAME --last-value LAST_VALUE --merge-key COLUMN_NAME --delete-target-dir --target-dir TARGET_DIRNormal Import as parquetfile
sqoop import --connect jdbc:mysql://HOST_NAME/DB_NAME --username USER_NAME -password PASSWORD -m 1 --table TABLE_NAME --delete-target-dir --target-dir TARGET_DIR --as-parquetfileNormal Import as avrofile
sqoop import --connect jdbc:mysql://HOST_NAME/DB_NAME --username USER_NAME -password PASSWORD -m 1 --table TABLE_NAME --delete-target-dir --target-dir TARGET_DIR --as-avrodatafileNormal Import default format text
sqoop import --connect jdbc:mysql://HOST_NAME/DB_NAME --username USER_NAME -password PASSWORD -m 1 --table TABLE_NAME --delete-target-dir --target-dir TARGET_DIR --as-textfileNormal Import --as-textfile
sqoop import --connect jdbc:mysql://HOST_NAME/DB_NAME --username USER_NAME -password PASSWORD -m 1 --table TABLE_NAME --delete-target-dir --target-dir TARGET_DIR --as-textfilecreateScoop job
scoop job --create sc_job --import --connect jdbc:mysql://HOST_NAME/DB_NAME --username USER_NAME -password PASSWORD -m 1 --table TABLE_NAME --delete-target-dir --target-dir TARGET_DIRimport all table
sqoop import-all-tables --connect mysql://host/dbname --username --password --warehouse-dir /user/cloudera/all_table --exclude customer8,customer9,customer10Sqoop Export :
Sqoop with AWS s3(form s3 to local db)
sqoop export -Dfs.s3a.access.key=ACCESS_KEY -Dfs.s3a.secret.key=SECRET_KEY -Dfs.s3a.endpoint=URL --connect jdbc:mysql://HOST_NAME/DB_NAME --username USER_NAME -password PASSWORD -m 1 --table TABLE_NAME --export-dir TARGET_S3a_DIRSqoop export
sqoop export --connect jdbc:mysql://HOST_NAME/DB_NAME --username USER_NAME -password PASSWORD -m 1 --table TABLE_NAME --export-dir SOURCE_DIRSqoop multi threading Normal Import with multi mapper (-m 4)
sqoop import --connect jdbc:mysql://HOST_NAME/DB_NAME --username USER_NAME -password PASSWORD -m 4 --split-by COLUMN_NAME --table TABLE_NAME --delete-target-dir --target-dir TARGET_DIRSqoop export with staging table for remove db lass
sqoop export --connect jdbc:mysql://HOST_NAME/DB_NAME --username USER_NAME -password PASSWORD -m 1 --staging-table STAGING_TABLE_NAME --table TABLE_NAME --delete-target-dir --export-dir SOURCE_DIR1)sqoop.export.records per statement
- It is to specify the number of rows that will be used in each insert statement.2)sqoop.export.statements.per.transaction
- We can determine how many insert statements will be issued on the database prior to commit transactionsqoop export
-sqoop.export.records.per.statement=3 --connect jdbc:mysql://HOST_NAME/DB_NAME --username USER_NAME -password PASSWORD -m 1 --staging-table STAGING_TABLE_NAME --table TABLE_NAME --delete-target-dir --export-dir SOURCE_DIRgoto 3 insert statement(per row) to hive default value is 100
sqoop export -sqoop.export.records.per.transaction=2 --connect jdbc:mysql://HOST_NAME/DB_NAME --username USER_NAME -password PASSWORD -m 1 --staging-table STAGING_TABLE_NAME --table TABLE_NAME --delete-target-dir --export-dir SOURCE_DIRSqoop export command helps in the implementation of operation. With the help of the export command which works as a reverse process of operation. Herewith the help of the export command we can transfer the data from the Hadoop database file system to the Relational database management system. The data which will be exported is processed into records before operation is completed. The export of data is done with two steps, first is to examine the database for metadata and second step involves migration of data.
Here you can get the idea of how the import and export operation is performed in Hadoop with the help of Sqoop.
Advantages of Sqoop :
With the help of Sqoop, we can perform transfer operations of data with a variety of structured data stores like Oracle, Teradata, etc. Sqoop helps us to perform ETL operations in a very fast and cost-effective manner. With the help of Sqoop, we can perform parallel processing of data which leads to fasten the overall process. Sqoop uses the MapReduce mechanism for its operations which also supports fault tolerance.
Disadvantages of Sqoop :
The failure occurs during the implementation of operation needed a special solution to handle the problem. The Sqoop uses JDBC connection to establish a connection with the relational database management system which is an inefficient way. The performance of Sqoop export operation depends upon hardware configuration relational database management system.